线性表
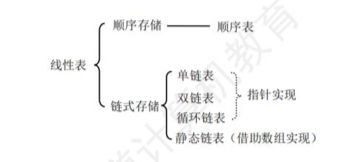
线性表根据存储结构可以分为:
- 顺序结构:顺序表
- 链式结构:链表
并且具有以下特点:类型相同、有限序列、有序
INFO
必须牢固掌握线性表的各种基本操作(基于两种存储结构),在平时的学习中多注重培养动手能力。
答题时,代码不一定具有可执行性,尽力表达出算法的思想和步骤,而且可以忽略边界条件判断
此外,采用时间/空间复杂度较差的方法也能拿到大部分分数,因此在时间紧迫的情况下,建议直接采用暴力法。
顺序表
c
typedef struct {
ElementType data[MaxSize];
int length;
} SqList;在一串连续物理地址上存储的顺序表,具有以下特点:
逻辑和物理上都相邻- 可随机存储,即R的复杂度为O(1)
高级程序语言中的数组是顺序表的一种表现形式,需要注意的是
- 顺序表的位序从1开始
- 数组索引是从0开始
根据容量是否固定,可分为:
- 静态分配:长度固定,数据空间占满时则会溢出
- 动态分配:一旦数据空间占满,将原表中的元素全部拷贝到新空间,从而达到扩充数组存储空间的目的。
INFO
假如之前顺序表长度为n而且已经占满,这时新增m个元素,那么则需要申请长度为n+m的连续空间
优缺点
优点:
- R、U快,直接从指针或者索引读取
- 存储密度高
缺点:
- C、D慢,原因是:每次插入和删除一个元素都需要变动许多数据元素的位置
- 要求物理地址必须连续,所以不够灵活
c
void reverse(SqList &L){
int a;
for(int i =0;i<L.length/2;i++){
a=L[L.length-1-i]
L[L.length-1-i]=L[i]
L[i]=a
}
}时间复杂度
- 插入:O(n)
- 删除:O(n)
- 查询:O(1)
链表
不需要连续物理地址上存储的顺序表,具有以下特点:
- 多占用一个空间指向下一个节点
- 非随机存储
分类
- 按照每个节点是否同时有前置和后继节点,可分为:
- 单链表
- 双链表
按照首位是否相接,也有循环链表。
构建链表时分为头插法(倒序)和尾插法(正序)
- 根据是否有头节点又可分为:带头节点、不带头节点

INFO
一般没有特殊说明,则默认链表为带头节点的
- 静态链表
连续地址存储的固定长度的链表
c
#define MaxSize 50
typedef struct {
ElementType data;
int next;
} SLinkList[MaxSize];以next==-1作为结束标志
单链表
c
typedef struct LNode {
ElementType data;
struct LNode *next;
} LNode, *LinkList;尾节点指向NULL,除此之外其他节点都有1个后继节点。因此非循环链表的判空条件是:尾节点的next指针是否为NULL
循环单链表

尾节点不再指向NULL,而是指向头节点构成1个环。
双链表
c
typedef struct DNode {
ElementType data;
struct LNode *prior, *next;
} DNode, *DLinklist;除了头节点和尾节点外,每个节点都有两个指针(prior和next),分别指向前驱和后继

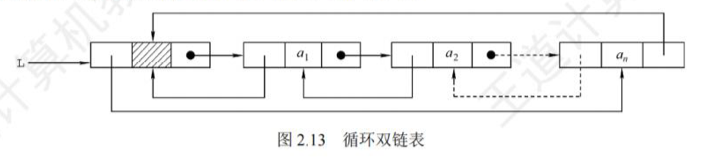
循环双链表
比较
顺序表与链表:
- 存取效率:前者高,后者低
- 物理地址是否连续:前者连续,后者不连续
- 查找
- 按值查找:两者均为O(n),但是前者有序时可以折半查找--O(logn)
- 按位查找:前者为O(1),后者为O(n)
- 删除和插入
- 前者平均需要移动半个表长的元素,O(n)
- 后者为O(n),但是不用移动元素
- 空间:前者效率低--需要移动大量元素,后者随用随申请,但存锤密度不大
- 后者更能反应逻辑结构
考察方向
- 双向链表的操作语句
- 尾节点与头节点结构推断
- 如果要删除一个节点,那么需要知道它的前一个节点。
- 对于循环链表,知道头节点指针,那么尾节点指针也知道
头节点 -> 首元节点 -> ... -> 尾节点