数据库设计相关
缓存穿透各个方案实现原理以及优缺点
非法查询请求、查询错误等问题导致没有命中缓存导致缓存没有有效分担数据库的查询压力,从而导致服务宕机或无法正常提供服务等问题
布隆过滤器
当一个元素被加入集合时,通过K个散列函数计算出位数组要映射的点位,并设置为1;检索时,只需要判断对应点位是否为1即可判断是否存在。如果为0则一定不存在,如果为1,则可能存在。本质是一个很长的二进制向量和一系列随机映射函数,用于检索元素是否在一个集合中。
优点:空间效率、查询时间
缺点:删除困难、存在一定的误识率
空置存储
没有命中缓存时从数据库中查询数据,并且在缓存中写入一个空值,方便下次查询时从缓存中取值。
优点:方便实现
缺点:浪费空间
缓存雪崩各个方案实现原理以及优缺点
在一段时间内,缓存中的值集体失效,导致查询压力转移到的数据库上。
随机设置缓存失效时间
使缓存失效时间分布更加均匀一些
热点数据永不失效
对热点数据不设置失效时间,并开启redis的持久化策略。
分布式部署
如果缓存是分布式部署,那么可以将热点数据均匀的分布到不同的缓存数据库中。
分布式缓存基本概念、方案以及切片方案
分布式缓存:将缓存横跨多台服务器存储,每个服务器负责存储缓存的一部分。
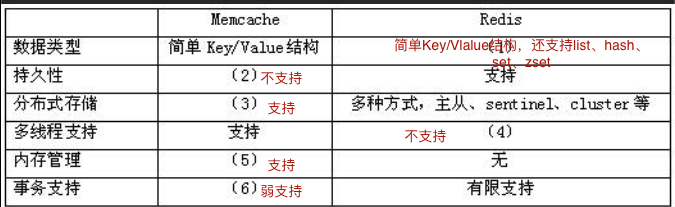
Redis和Memcache区别
Redis与Mysql常见同步方案
- 读数据时,先从缓存中取数据,如果没有命中缓存,那么从数据库中查询数据,将查到的数据再回写到缓存中;写数据时,先更改数据库中的数据后删除缓存。
- 数据库中间件,实时同步数据库中的最新数据到缓存。
写case中,删除缓存和更新数据库操作先后顺序问题
由于多并发情况下发起网络请求的时间不同、数据库的查询和更新操作时间不同,而且操作过程都有可能存在失败的情况等这些因素都会影响缓存和数据库中的数据不一致。
Redis分布式方案
- Cluster:将集合中的数据分布到多个Redis实例中存储,每个Redis实例负责存储缓存的一部分。
- 主从复制:将一个主Redis实例中的数据复制到其他从实例中,而且顺序是单向的,只能是主到从复制,提高了缓存的可用性(主动冗余)
- 哨兵模式:在一主多从的集群环境下,当主服务器宕机时,无需人工干预自动在从服务器中选举出主服务器。