Unicode与ASCII
ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语
其扩展版本延伸美国标准信息交换码则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
问题
ASCII的局限在于只能显示26个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语
ASCII扩展版本(EASCII)解决了部分西欧语言的显示问题,但对更多其他语言依然无能为力
Unicode
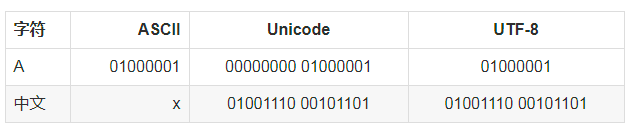
Unicode把所有语言都统一到一套编码里,因此又称为万国码。常用两个字节表示一个字符,但是如果要用到非常偏僻的字符,就需要4个字节。
UTF-8
为了降低存储空间,把Unicode编码转化为“可变长编码”的UTF-8编码,而且UTF-8编码兼容ASCII。
INFO
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
例如:
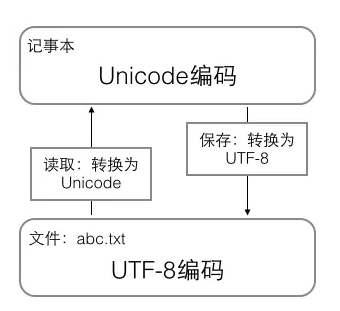
- 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
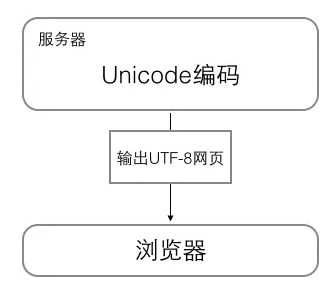
- 浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
参考:
【2】wiki#Unicode
【3】wiki#ASCII
【4】wiki#UTF-8